機器翻譯進展及澳門研究展望*
李怡平(澳門大學科技學院)
摘要
人們在電腦出現初期已開始應用計算機翻譯自然語言的研究,走過了五十年的曲折道路後,機器翻譯的研究成果終於得到廣泛應用。本文概述機器翻譯研究的歷史經驗、成果現狀、和技術發展的新趨勢。澳門對機器翻譯的需求、開展這項研究和開發工作的必要性、可行性、以及研究和開發工作規劃亦在本文討論。本文最後介紹在澳門已開展的有關機器翻譯研究的一些學術活動以及已進行的一些研究工作。
Advances MT and Its Researches in Macau
Li Yi Ping(Faculty of Science and Technology,univerity of Macau)
Abstract
Computerized translation of natural languages started when digital computers were available. After fifty long years, a number of machine translation (MT) systems are eventually used by governments, businesses and industries around the world. A briefhistory, the current status, and the trends of MT are observed in this paper. It is imperative and feasible for Macau to develop a Portuguese-English-Chinese multilingual machine translation system. An international co-operation with MT research groups from Portugal and China was proposed. In Macau a sub-project has been started which initial result is also presented.
Desenvolvimento e Investigação em Tradução Automática por Computador em Macau
Li Yi Ping(FST, Universidade de Macau)
Sumário
A tradução automática por computador das linguagens naturais teve início quando os computadores digitais passaram a ser utilizados. Após cinquenta longos anos, um dado número de sistemas de tradução automática por computador são eventualmente utilizados por governos, empresas e indústrias em todo o mundo. Uma breve resenha histórica, o estado actual e as tendências da tradução automática por computador são consideradas neste trabalho. Ê imperativo e viável para Macau desenvolver um sistema de tradução multilingue automática para Português-Inglês-Chinês. A cooperação internacional com grupos de investigação em tradução automática por computador de Portugal e da China, foi proposta. Em Macau foi iniciado um subporjecto cujos resultados preliminares são também apresentados.
一、機器翻譯五十年
人類自然語言的翻譯是數値計算機最早的應用之一。實際上,用機器翻譯的構思出現於本世紀初,比翻譯用的機器的出世早得多。但是僅在第二次世界大戰後的1946年,當數値計算機眞正運作時,Warren Weaver和A.Donald Booth等人才開始翻譯計算機化的硏究。
機器翻譯的發展可以分爲三個階段。第一階段從五十年代到六十年代初,此爲嘗試階段。1954年在喬治城大學(Georgetown University)演示的“喬治城自動翻譯機”(GAT)系統獲得成功。當時,機譯的硏究項目方興未艾,硏究經費滾滾而來。但是十年後,1966年,美國國家科學院語言自動處理諮詢委員會(ALPAC)發表了黑皮書《語言和機器:翻譯和語言中的計算機》,作出發展機器翻譯技術“得不償失”的結論。這就是頗具爭議性的ALPAC報告。它使美國的機器翻譯硏究一度嚴重受挫,可慶幸的是世界範圍內的機器翻譯硏究仍在進行。
從六十年代初到七十年代末爲第二階段。這是調整和開始實用的階段。英國和日本的機器翻譯硏究起步要比美國遲十年。法國的GETA系統於1960年在巴黎建立,後來在Grenoble發展。自ALPAC報告後,美國仍有幾個公司和實驗室堅信機器翻譯將會“柳暗花明又一村”。結果,Systran系統建立、擴展、並投入實際應用。Logos也是在ALPAC報告時期成立。它的目標也是開發應用型系統。這個階段以1980年在日本召開的計算語言國際會議(COLING—80)作爲結束。那是一次標誌着機器翻譯復甦的會議。
第三個階段從1980年至今,爲迅速增長和擴展服務的階段。電腦網絡、工作站和個人計算機等技術的進步已爲更多的用戶提供更廣泛的機器翻譯服務。經歷過第二階段,人們已經認識到ALPAC報告的片面性。理論語言學、計算語言學和人工智能硏究的新成果已經解決或正在解決機器翻譯中的許多理論問題。越來越多的實用型機器翻譯系統的開發和運行成功使正在高速進入信息時代的社會增添了強勁的發展動力。
二、機器翻譯系統的類型
歐美現有的機器翻譯系統,按功能分類大體上可以分爲五大類。按其功能由弱到強排列有單一語料型、簡化語言型、人機交談型、批處理型和通用型。
單一語料型系統專用性強,僅能從事某一專題的語言材料的翻譯,效果良好,但不能翻譯其它題材的材料,這類系統主要用於硏究工作。
簡化語言型系統可以翻譯經過簡化的語言材料。可以對用自然語言書寫的原文進行譯前編輯簡化,也可以用簡化了的句法和詞匯來寫作原文,如美國施樂(Xerox)公司的SYSTRAN、加拿大聯邦政府翻譯局的METEO以及法國紡織硏究所的TITUS。
人機交談型系統的特點是:機器和譯員協同工作;當機器遇到語法分析(parsing)或歧義處理方面的問題時,便向譯員求助,得到解答後再繼續往下譯。不同的系統需要人工干預的程度各不相同,但所有的系統都要求譯員在原文分析和詞典編制方面提供幫助。目前正在硏製的各類機譯系統,無論是大型機上用的,還是個人機上用的,都會帶有某種交談式的因素。
批處理型又稱,“詞典易於更新式批處理型”。該類型的系統工作時先輸入全部原文,再由機器查閱詞典,然後一次性產生全部譯文。系統在查閱了自身所帶的詞典後,往往還會請譯員輸入與所譯文本主題有關的詞項,以屏幕提問的方式讓譯員輸入這些詞項的詞法、句法和語義信息。這些信息可直接用於機器詞典的更新。
通用型實際上是批處理型的高級形式。它的目標是翻譯所輸入的任何材料(當然,翻譯質量會因所譯材料的性質不一同而有高低之分)。這類系統對原文分析的可靠程度較高。機器詞典容量很大,包含大量的語義編碼。以前這類系統需在大型計算機上運行,現正逐步移植到個人計算機系統。
機譯系統也可以按照自動化程度來分類,其自動化程度可由翻譯人員與機器交談過程中(生成原始輸出前)所需的時間來衡量。按此分類則有機助人譯(MAHT)、人助譯機(HAMT)和全自動機譯(FAMT)等三類。
機助人譯(MAHT)基本上是人在翻譯。他利用的機器輔助是有限的。翻譯人員在此系統中可以得到下列輔助;帶詞典的文字處理系統、上下文關鍵詞工具、語法資料、詞法分析、翻譯文章的語料庫以及拼寫和語法的修改。
人助機譯(HAMT)系統的運行需要翻譯人員的協助。當某些語言結構難於進行自動分析,或者某些單詞有多種意義時,機器會向翻譯人員求助。例如:確定連接詞(‘and’,‘or’等)的作用範圍;在句子中分隔開一連串的名詞;指出介詞的功能;解決一詞多義的問題等。
全自動機譯(FAMT)系統運行時,從輸入原文本到最後輸出原始翻譯之間,不需要任何人員的參與。當然,“全自動”並不是不需要翻譯人員的後修改或者後編輯工作。
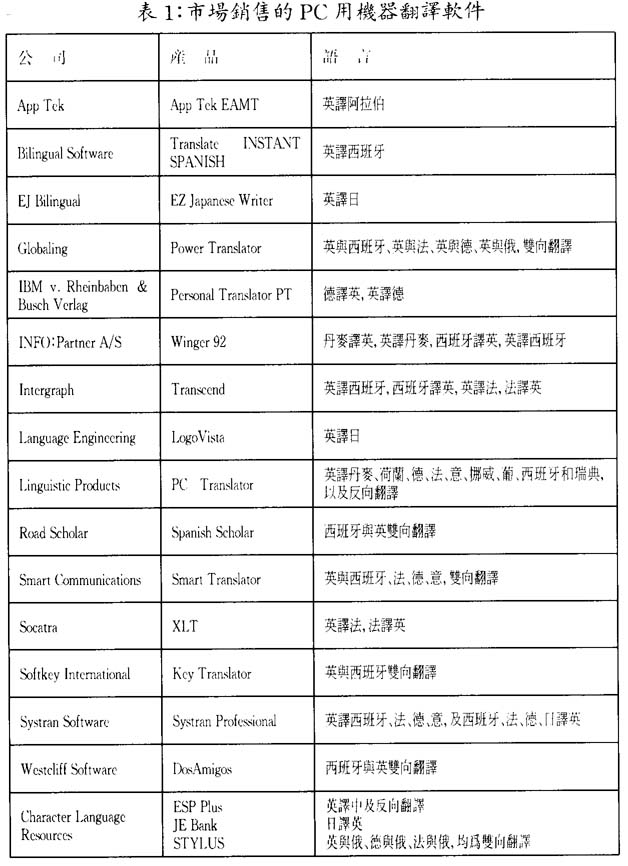
如按系統工作的硬件平台來分類,又可以分爲主機型系統、工作站型系統和PC機譯系統。我們在下一節將看到,發展PC機譯系統已成爲新的趨勢。表1爲目前部分歐美公司推出市場的用於個人機的機譯系統產品。這些資料選自最新的國際機譯通訊(MT News International,No.12,October,1995)。
三、機器翻譯新趨勢
根據1995年的資料,新的機譯系統發展有四大趨勢:基於個人電腦的機器翻譯系統迅速增長、機器翻譯聯機應用出現高潮、機器翻譯的使用多元化、和狹義機器翻譯系統與機器輔助翻譯系統的差別逐步縮小。
PC機譯 原來龐大的機器翻譯系統現在有了便於普及的PC套裝。在1995年的上半年,機譯的兩大公司SYSTRAN和Intergraph開始以低售價推出PC窗口版本。這些新版本保留了原先在工作站和主機上運行的所有功能及容量。兩者都可以處理大型文件,都有大範圍的語言對組合。
Globalink的PC版機譯軟件已遍佈市場,現在新一代的窗口翻譯軟件即將推出。它們具有大規模的轉換系統的全部特性,包括用戶友善工具以讓用戶寫出處理複雜語法結構。丹麥系統Winger92還有“專家”版,可讓用戶修改現有的語法。
IBM/Deutschland組織德國電子出版專業人員推出了一張叫個人翻譯器的CD-ROM,價錢相當低(199—499馬克),可以作英-德翻譯。它由LMT(基於邏輯的機譯系統)發展起來,目標是非專業市場。在1995年5月投放前,IBM在德國已收到一千多訂單。
這些產品如此受歡迎,是因爲它們的功能強勁而價格低廉。即使在這些新產品未問世之前,陳列在電腦商店貨架上的廉價PC 機譯軟件已吸引着衆多用戶躍躍欲試。首先打入大衆市場的是MicroTac的語言輔助系列。它的窗口版僅售59美元,在街上出售的甚至更便宜。顯然,價格越低,想試用的人就越多。到1994 年底,這個系列軟件已售出四十萬套。
線上機譯 另一個影響更加深遠的發展是現在機譯已在計算機空間接觸到大量的用戶。過去SYSTRAN、ATLAS、PIVOT和Globalink提供不同程度的半加工輸出的聯機服務。現在機譯開拓了讓用戶聯機通話的新服務項目。1994年CompuServe在MacCIM區域推出了Intergraph系統,在1995年3月大衆論壇開幕典禮上,這個機譯系統使與會者能用英、法、德、西班牙以及線上的其它語言交流。頭四個月期間,約一萬五千用戶參加了這個論壇,其中至少有一半現在已成爲固定用戶,他們已在線上傳輸了兩萬六千條電文。
CompuServe和Globalink同時都在加快步伐,不僅供應聯機半加工的機譯結果而且也按客戶的要求提供全部後編輯的翻譯。翻譯客戶很快就能在桌面上將他們的文本提交給其中一個聯機服務中心而用信用卡結帳。
在另一機譯聯機的創造性應用中,Global在美國的分部在國際聯網使用它的語言助理系統(Language Assistant)去召集全球16所中學一起。學生們用英、法、西班牙及意大利文寫他們自己的故事和家庭,然後通訊交換。
應用多元化 至1993年仍然祇有兩類機譯用戶:大量應用高檔機譯系統製作技術手冊的工業界大戶和使用廉價機譯系統去摘錄信息或交流短文的非固定用戶。毫無疑問,技術文獻的出版翻譯仍然是機器翻譯的主要應用;同時,許多其它重要的應用正在出現,其中不少非翻譯專業人員用來捕獲無人翻譯的文件內容。現在PC機譯系統可以用來借助關鍵詞搜索文獻。以前祇有軍事和工業監視機構使用的大型機譯系統才能做到這點。
桌面集成化 隨着廉價PC產品大衆化的衝擊,Unix工作站系統的經營者再也不能忽視PC桌面的存在。SYSTRAN爲它的PC機譯產品提供了網絡版本,而LOGOS和METAL爲窗口用戶提供軟件,讓PC用戶能向這兩個基於Unix的機譯系統遙送需翻譯的文件。現在幾乎都認識到機譯系統必須推向用戶,也就是進入到PC用的如WordPerfect、Word和AmiPro等文字處理環境中去。
從另一方面來看,機器翻譯和機器輔助翻譯的差別正在逐漸縮小。曾經是專用的高檔機譯系統變爲交談式和桌面化。而傳統的桌面翻譯輔助工具如術語管理、翻譯存儲和聯機引用等功能正在集成爲一個翻譯系統。令人印象深刻的“翻譯工作站”套裝就是這一變化的結果。它利用自動和人工翻譯各自優勢,力圖改進整個文件生成周期。
四、澳門與機器翻譯
澳門在促進東、西方文化交流方面起着重要的作用。由於葡文和中文都爲官方語言,行政事務對翻譯的需求驚人地增長。不僅政府的新文件需用雙語發表,而且大量的現存葡語文件,如法律文件,仍待翻譯成中文。
澳門居民來自世界各地。除中、葡文以外,英文也在某些敎育機構、科技中心和商貿部門裡使用。很難想像沒有機器翻譯系統如何推行辦公自動化。
澳門還是一個吸引數百萬外國遊客的國際城市。除了旅遊業以外,出口貿易也是澳門的一項重要的外匯來源。澳門的發展還依賴於從發達的工業國家吸收和引進技術及設備。這些活動都表明澳門對翻譯服務的需求十分迫切。
澳門對翻譯的需求量不會比世界其它地區低,對這點大槪沒有人懐疑。但是對於使用機器翻譯是否能夠事半功倍就將信將疑了,因爲市面上的袖珍電子詞典翻譯句子的功能實在不敢恭維。不過我們應知道,電子詞典的句子翻譯僅是它的附屬功能,而且它是面向旅遊者的,僅可以爲在異鄕生活的外國遊客提供幾句基本用語。實際的機譯系統無論從運行速度和詞典庫容量都比袖珍型大得多。詞典對機譯的質量有着重要的影響,翻譯不同題材的文章還要配備不同的專業詞典。有些機譯詞典的容量已超過幾十萬條。有資料統計說,世界上30%到50%的翻譯已由翻譯機器完成(當然人工的後編輯仍不可少)。一般,後編輯人員使用機譯系統工作,其效率比傳統的人工翻譯成倍提高,一個八小時的工作日可完成3000到10000個詞。目前,機譯祇能完成翻譯過程的一部分。即使如此,它已將成本從純人工翻譯的每頁35至90美元降低到機譯加人工後編輯的10至30美元。
旣然應用機譯系統有可觀的效益,在澳門當然應該加以推廣。但是我們是否有必要自己來硏究和開發此系統。何况市場的機譯產品如此廉價,直接買來使用豈不更直接了當。可是我們應該知道,葡中翻譯軟件是專用軟件,它不同於Pascal或C語言等通用軟件。由於市場的地域窄和客戶少等因素限制,目前還未有葡漢機譯系統面世,即使是葡英系統也仍在開發中。筆者曾搜索過有關動態資料,並曾聯繫過有計劃硏製葡中機譯軟件的公司。結果寄去的信函如泥牛入海,這些公司最後連傳真號也關閉了。
按照目前的技術水平,全自動的機譯系統還難以實現。即使在市場上可以得到現成的機譯系統。使用時還需要人工的預編輯或後編輯處理,不同的使用對象還有對系統的詞典庫和轉換規則進行更新和擴充的工作,解決這類二次開發技術問題還須有具備機譯技能的人材。進行機器翻譯的開發和硏究工作是培養和訓練這類人才的最好途徑。歐共體耗資龐大的機器翻譯硏究和開發項目EUROTRA的最大效益是爲歐共體各成員國培養了一批掌握機譯技術的骨幹力量。“國際電腦合作中心(CCIC)在1987年開始了一項硏究和開發多語言機器翻譯系統的計劃。目標是機器翻譯多國語言:日文、中文、印尼文、馬來文和泰文。這個項目啓動和促進了東南亞各參加國對機器翻譯的硏究工作。機器翻譯是信息化社會的一門重要技術,澳門應該在這方面建立自己的技術力量。
在澳門如何規劃機器翻譯的硏究開發工作?根據澳門的實際情况,筆者認爲,我們的硏究工作應該面向應用。近期內可以先建立並完善一個葡中機器詞典,任何機器翻譯系統都需要機器詞典,詞典的質量對翻譯的結果影響很大。我們在這方面已邁出了一步,在下一節將作介紹。除詞典外,澳門應建立葡中雙語語料庫。因爲葡文和中文均爲官方語言,現已積累大量的雙語對照文本。如將它們轉換成機器可讀的語料庫。那將是一個用途非常廣的數據庫,其中之一的用途是用來翻譯新的文件。我們的系統開發可以從機助翻譯系統開始,機器詞典是這個系統的基礎。以後逐步增加系統的功能模塊,成熟一塊,應用一塊。最終將完善一個功能較全、自動化程度較高的機譯系統,而這個系統從開發初期便可以使用,收益快、效率高。
從長期的目標看,我們應尋求國際間的合作。中國和葡萄牙的同行都是理想的合作伙伴。中國在機器翻譯方面已有了可喜的成就,中軟公司(CS&S)於1992年已將英漢機譯系統:譯星(Transtar-92)投放市場。該系統在PC-486上運行每小時可處理三萬個英文單詞。該公司還於1993年推出漢英機譯系統SinoTrans。葡國的同行在機器翻譯方面也有豐富的經驗,MENTOR爲IBM與INESC合作開發的葡文機器翻譯系統的原型。
1994年3月,澳門大學主持召開了一個有來自中葡兩國的機器翻譯專家參加的硏討會。在會上各代表介紹了他們各自的機器翻譯硏究現狀,討論了合作項目的可行的硏究方法和技術方案。
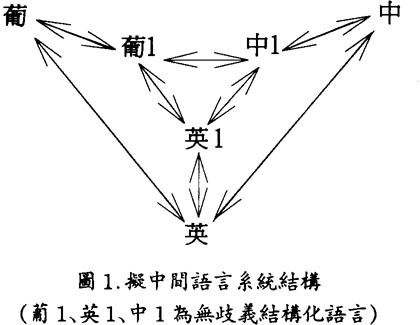
這次會議曾考慮過採用中間語言(Interlingua)方案。這種方案以中間語言作爲樞紐,系統中各語言對之間的翻譯均通過中間語言實現,源語言和目標語言之間不需要進行直接翻譯。這樣便於分塊開發,而且在一個系統中語言較多的情况下能夠大大節省開發工作量。但是中間語言至今仍未有國際標准,目前它作爲硏究對象仍有大量工作可做,但作爲開發工具並不省時或省工。我們吸收中間語言方案的長處,提出了一個新的擬中間語言結構方案。如圖1所示,以無歧義及結構化的語言組合代替中間語言。在此系統中,英葡及英中的機譯系統已有成果,我們僅需要開發葡中機譯子系統。因爲其中的“葡1”與“中1”語言已經是無歧義和結構化,它們之間互譯的實現也就比較容易。
會議還確定了工作計劃,最後就聯合硏究和開發葡英中多語言機器輔助翻譯系統達成共識。聯合方案已經提出,目前各方代表正在分頭尋求對這個項目的資助,爭取早日立項。
爲了配合這個合作項目的工作,從1994年開始,澳門大學的硏究委員會已特別資助校內相應的硏究項目。下面介紹的是我們在這些硏究項目裡取得的一些初步成果。
五、一個葡英漢機助翻譯工作站
目前486在澳門已是普及機型,而MS-Window已是普遍採用的運行環境。所以我們選擇MS-Window作爲開發平台。它提供了一整套功能強的函數庫,使圖形界面程序的開發變得相當容易。在窗口環境中運行的軟件可移植性好,與硬件平台無關,可應用任何類型的監視器和打印機。
該系統提供交談式的圖形用戶界面。它包括下列功能:編輯器——可編輯葡語、英語和漢語文件;數據庫管理系統——提供高能多用戶的葡英漢字典和葡語拼寫檢查;圖形用戶界面及模塊之間的界面;內碼轉換工具——GB碼和BIG5碼雙向轉換;外掛工具——提供接口外掛OCR文件讀入器。
編輯器要處理中、英、葡等多種文字,故除英文字型外,還備有葡文、簡體漢字和繁體漢字的字型。由於漢字和某些葡文字都在第一字節的最高位置1,目前本系統未能區別這幾種文字。祇設計了肖像(icon)用作這幾種文字之間的一致轉換。
數據庫管理系統可分三層描述。在首層,該系統分爲下列四個子模塊:系統初置和關閉模塊,詞典模塊,拼寫檢查模塊和內部函數模塊。在第二層,每個模塊由函數構成。系統初置和關閉模塊有三個函數:InitDB-初置系統和開啓數據庫,CreateDB-建立數據庫,以及CloseDB-關閉系統和所有數據庫;詞典模塊有六個函數:SearchPD-用葡文單詞作爲關鍵詞搜索PEC數據庫,SerachCPD-用中文單詞作爲關鍵詞搜索PEC數據庫,GetPD-用葡文單詞從PEC數據庫檢索解義信息,以及它的復數式、陰性式或陰性復數式,GetCPD-用中文單詞從PEC數據庫檢索解義,SavePD-將新詞存入PEC數據庫,並將相應的復數式和陰性式加入拼寫檢查數據庫,TextT0PD-從批處理文件讀取新詞目並存入PEC數據庫;拼寫檢查模塊的設計與PEC詞典模塊的設計相似,但這裡不需要處理批文件。它有三個函數:SearchPW-查拼寫檢查數據庫以獲得比較表,GetPW-查葡文詞是否在拼寫檢查數據庫,SavePW-將葡文單詞加進拼寫檢查數據庫。第三層涉及每個函數的具體設計。這裡略去其細節。
內碼轉換器是爲漢字內碼的轉換而設。內地統一使用國標(GB)碼。港澳台地區使用的內碼五光十色,其中BIG5碼較爲普遍。本系統的內碼轉換器包括GB到BIG5和BIG5到GB兩部分。轉換通過直接影射實現,這樣可以簡化轉換過程。需要注意到的是從GB到BIG5的影射象簡體字對繁體字一樣,有可能是一碼對應多碼。這種情况讓用戶去選取恰當的轉換結果。
外掛工具主要是OCR工具,包括閱讀葡文和中文的OCR工具。這些工具非常有用,可以大大減輕要處理的源文件輸入的工作量。
系統的圖形用戶界面槪貌在圖2給出。
本系統的性能決定於數據庫的規模。如數據庫的紀錄超過兩萬條,系統性能將下降。影響的性能主要是索引中文詞,中文相應詞這一字段在數據庫中不是主索引字段。相反,葡文單詞拼寫檢查的性能相當好,因爲所有搜索運算都靠索引。
爲提高搜索速度,我們可以將整個詞典分解爲幾個數據庫,每個數據庫包括的詞目有相同的首字母。這樣可以減低詞典的容量而提高系統的性能。
目前,詞典的內容正在充實中,今年初已裝入三萬個葡文詞匯。
* 澳門大學研究委員會資助項目。
參考文獻
(1)陳肇雄主編,《機器翻譯硏究進展》,電子工業出版社,1992
(2)柯平,歐美的機器翻譯,《中國翻译》,第2期,1995
(3)李怡平,機器翻譯及澳門硏究,《澳門硏究》,第3期,1995
(4)李怡平、潘治文等,一個葡英漢機助翻譯工作站,待發表
(5)EUROTRA Final Review Panel Report, 1993
(6)Campbell and J. Cuena, Perspectives in Artificial Intelligence,Volume Ⅱ: Machine Translation, NLP, Databases and Computeraided Instruction, Ellis Horwood, 1989
(7)Colin Brace, Muriel Vasconcellos, and L. Chris Miller, MT users and usage: Europe and the Americas, MT News International,October 1995
(8)Sara Hedberg, Machine Translation comes of age, AI Expert,October 1994
(9)John Lehrberger and Laurent Bourbeau, Machine Translation,Linguistic Characteristics of MT Systems and General Methodology of Evaluation, John Benjamins, 1988
(10)Klaus K. Obermeier, Natural Language Processing Technologiesin Artificial Intelligence, The Science and Industry Perspective,Eillis Horwood, 1989
(11)Eugenio Picchi,Carol Peter, & Elisabetta Marinai,A translator's workstation, Proc. of COLING - 92, Nantes, 1992
(12)Darmawan Sukmadjaja, Machine translation research in Indonesia, MT News International, Issue no. 8, May 1994
(13)Muriel Vasconcellos, Machine translation, Byte, January 1993
